Classify and extract data from scanned documents with TeleForm Reader
Once the scanning is complete, the images are sent to TeleForm Reader for image processing, document classification and data extraction.
The Reader module runs in the background day and night, handling the collection and interpretation of images from the scanner, fax server, and/or a network directory.
Image processing
At this stage, the images will undergo image conversion and pre-processing. Before data can be read from the image, it needs to be cleaned up. During image pre-processing on scanned images, TeleForm Reader will:
- check the page size and adjust if necessary
- check orientation and rotate if necessary
- convert colour images to black and white for best recognition results
- remove image defects e.g. skewing, noise and stray marks
The process will also involve confirming barcode readability, checking the presence of cornerstones and page linking.
Image classification in TeleForm Reader
TeleForm eliminates the need for manual sorting; it automatically classifies and evaluates the images by comparing them to templates created in the TeleForm Designer. Initially, TeleForm looks for its own identification blocks within the image, if these are not found it can fall back to page comparison, comparing layouts, wording and even logos, to classify the document.
Extract data from scanned documents using OCR, ICR, OMR and barcode recognition
After classification, handprint (ICR), machine print (OCR) and checkbox (OMR) recognition technology will extract data from the scanned document. This will include constrained print fields, tick boxes, variable scales, comments, tick boxes and signatures.
The following document recognition technology is used to extract data from paper surveys and forms:
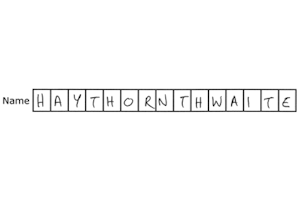
Intelligent character recognition (ICR)
To read short hand-print written responses from constrained print fields (one character per box) such as names, dates and numbers.

Optical mark recognition (OMR)
OMR technology identifies if a checkbox has been filled, with automatically handling of crossed out and amended responses.

Optical character recognition (OCR)
To capture machine printed text.

Image zone capture
Predictive key from image, coding and image snippet capture can be used to capture drawings or cursive handwriting.

Barcode recognition
To recognise all standard barcode types, including 2D matrix barcodes.

Signature detection
To confirm if a paper form has been authorised with a signature by calculating the fill percentage of the field.
Simple rules such as alpha, numeric, dictionaries, date ranges, look-ups and mandatory fields will be checked at this stage with any unrecognised fields/characters queued for human review.
These common-sense logic rules are applied to the extracted data to ensure that invalid responses are not exported (e.g. impossible to tick more than one response for a single-choice question). In such situations, TeleForm will queue the offending fields for human verification.
