
Intelligent document recognition and data extraction
Once the scanning is complete, the images are submitted for image processing, intelligent classification, document recognition, and data extraction.
Once the scanning is complete, the images are submitted for image processing, intelligent classification, document recognition, and data extraction.
Image quality is a critical factor in determining how well characters and documents are identified and processed.
Automated data capture software includes advanced image enhancement and correction capabilities, including de-skewing, auto-rotating and character enhancement.
Built-in quality control features identify and correct low-quality images early in the process to reduce human intervention.
Each image received will be compared to one or more pre-defined templates to identify the form type. The software can recognise and distinguish between many different form types and process them accordingly. Unrecognised pages (such as cover pages or damaged pages) will be routed to an unclassified queue for manual handling.
After document processing and classification, data capture software uses handprint (ICR), machine print (OCR) and checkbox (OMR) document recognition technology to automatically extract data from scanned documents. This will include constrained print fields, tick boxes, variable scales, comments, tick boxes and signatures.
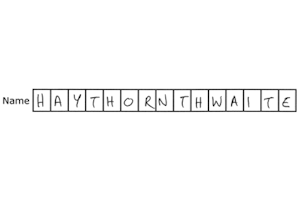
To read short hand-print written responses from constrained print fields (one character per box) such as names, dates and numbers.

OMR technology identifies if a checkbox has been filled, with automatically handling of crossed out and amended responses.

To capture machine printed text.

Predictive key from image, coding and image snippet capture can be used to capture drawings or cursive handwriting.

To recognise all standard barcode types, including 2D matrix barcodes.

To confirm if a paper form has been authorised with a signature by calculating the fill percentage of the field.
Simple rules such as alpha, numeric, dictionaries, date ranges, look-ups and mandatory fields will be checked at this stage with any unrecognised fields/characters queued for human review.
These common-sense logic rules are applied to the extracted data to ensure that invalid responses are not exported (e.g. impossible to tick more than one response for a single-choice question). In such situations, the exception will be intelligently routed to the right human operators to review and correct. The entire process takes seconds meaning thousands of forms can be processed each day.
We select the best data capture systems to meet your requirements.

TeleForm automatically captures and indexes data and images from any form type, using handprint (ICR), machine print (OCR) and checkbox (OMR) recognition technology, ready for export to a database.
It aims to reduce manual data entry time by 90% or more and can eliminate hundreds of operator keystrokes.
ABBYY FlexiCapture is a highly scalable forms processing solution for intelligent and accurate extraction of data from structured, semi-structured and unstructured forms and documents for input into backend applications for further processing and archiving.
Based at the University of Bristol, the ‘Children of the 90s’ study uses TeleForm to capture data from the paper versions of their questionnaires.
Following a OJEU tender process, the British Council commissioned Civica as the prime contractor to deliver an on-screen marking (OSM) solution to mark up to 5 million ‘pen and paper’ IELTS tests each year.
As part of the agreement, Civica appointed ePC as its sub-contractor for the script capture, processing and verification work.

Keele CTU saves time by capturing data from paper-based clinical trials with TeleForm.